AutoML Solutions: What I Like and Don’t Like About AutoML as a Data Scientist
23 min readThis blog post was written by me and orginally posted on Neptune.ai Blog. Be sure to check them out. I like their blog posts about MLOps a lot.
There’s a sentiment that AutoML could leave a lot of Data Scientists jobless. Will it? Short answer – Nope. In fact, even if AutoML solutions become 10x better, it will not make Machine Learning specialists of any trade irrelevant.
Why the optimism, you may ask? Because although a technical marvel, AutoML is no silver bullet. The bulk of work a data scientist does is not modeling, but rather data collection, domain understanding, figuring out how to design a good experiment, and what features can be most useful for a subsequent modeling/predictive problem. The same goes for most ML engineers and other data professionals.
Indeed, AutoML sounds like some sort of algorithmic magic, that upon receiving your labeled data, will output the best possible ML model for it. Truth be told, AutoML is a bit like interacting with a genie: “Be careful what you wish for”, or rather, what data you give it.
Remember the saying, garbage in – garbage out? Due to the additional feedback loops in an AutoML system, compared to a classic ML solution, the “garbage” will be amplified beyond your wildest imagination. I personally wasn’t careful enough and fell into this trap a few times, but more on that later.
Before making any more claims, we first need to understand what AutoML is, and what it isn’t.
The current state of AutoML
In practice, AutoML can take quite different forms. Sometimes a relatively efficient hyperparameter optimization tool (HPO), which can pick different ML algorithms, can be called an AutoML tool. A few notable examples are TPOT, AutoKeras, and H2O.ai AutoML (not to be confused with Driverless.ai). I could even speculate that given a GUI/Web interface to interact with these kinds of tools, and enough marketing budget, one can create a startup out of these.
For some Deep Learning folks, AutoML would be about NAS, aka Network Architecture Search algorithms or methods. These methods are actually a very interesting research direction, which brought us such computer vision architectures as EfficientNet, AmoebaNet, and methods like DARTS, ENAS, and PNAS. A couple of notable open-source tools for NAS are Microsoft’s NNI and MXNet AutoGluon.
Recall my speculation about HPO + nice interface == profit? It was more of a simplification, but some companies actually did this, of course adding features, scalability, security, and customer service, and it works, and it indeed helps organizations enable data scientists to solve a lot of problems. H2O’s Driverless.ai is probably the most well-known solution of this kind, but part of DataRobot and Dataiku’s products are also managed AutoML behind an easy-to-use interface.
I believe a special mention is for AutoML offerings from cloud giants like Google, Azure, and AWS. I don’t have much experience with Azure and AWS, but I can speak about my experience with Google’s Vision AutoML. From my experiments and knowledge, these solutions are some of the few that actually use NAS in a developer-oriented product and this is amazing.
Note that the NAS won’t be used for quick runs. The last time I checked, specifically Google Vision AutoML was using Transfer Learning for quick runs and NAS for 24-hour runs. It’s been a while since I checked though.
Let’s structure all of this information a bit, shall we? The table below should give you a high-level sense of how different tools are AutoML, in one way or another.
| Name | Is it Open Source? | On-prem/Managed? | Features | Kind |
|---|---|---|---|---|
| Microsoft NNI | Yes | On-premise | HPO + NAS + Some other interesting stuff | NAS, has a Web UI |
| AutoGluon | Yes | On-premise | NAS, supports penalizing big models | NAS |
| AutoKeras | Yes | On-premise | NAS, depending on scenario has baselines it tries first | NAS |
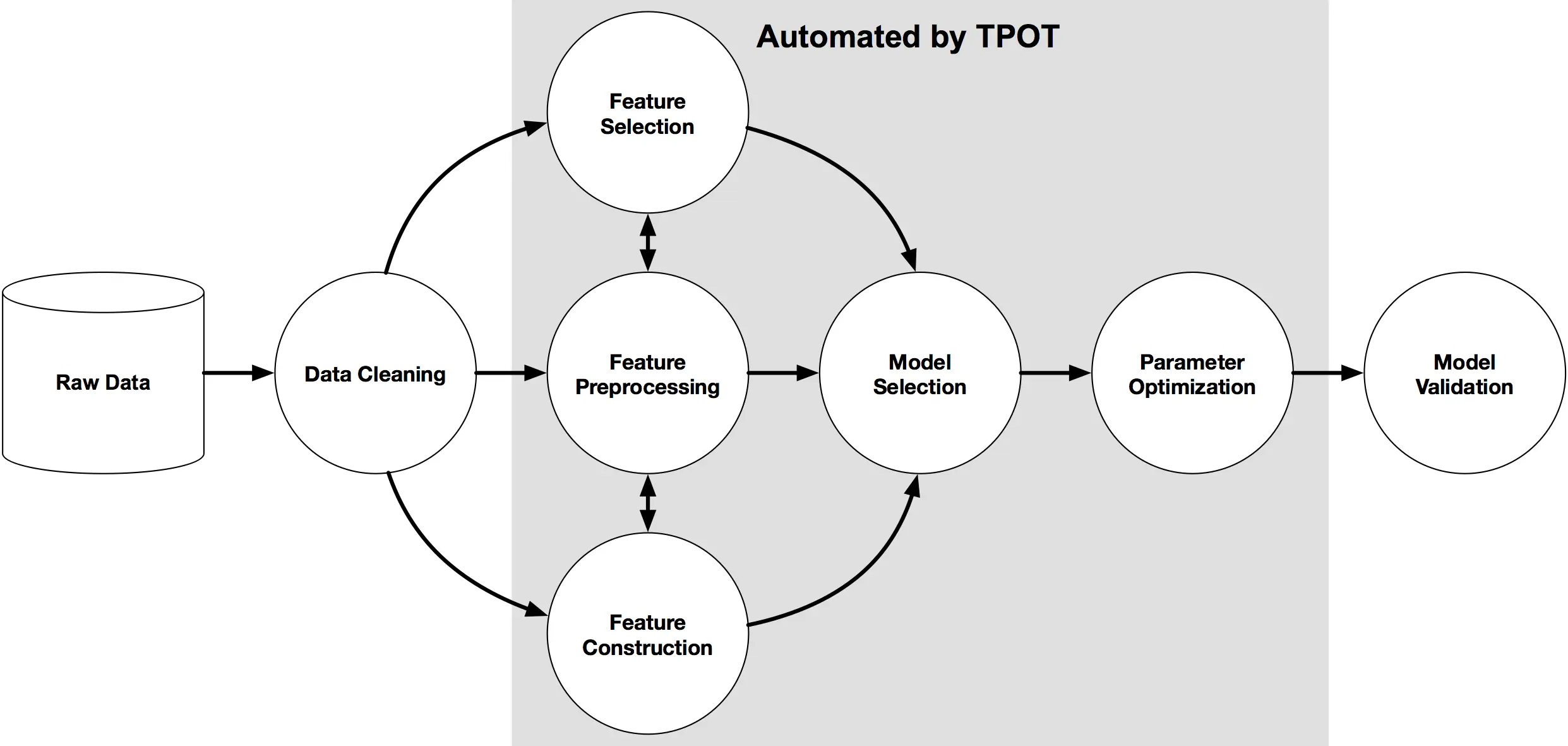
| TPOT | Yes | On-premise | Builds pre-processing + algorithms + ensembles pipelines | HPO++, actually uses genetic algorithms |
| H2O.ai AutoML | Yes | On-premise | Basically a free version of Driverless.ai | HPO++, has a Web UI, w\ integrated evaluation |
| H2O Driverless.ai | No | On-premise | Uses many pre-processing, feature encoding and selection schemes | HPO++ with a nicer UI, w\ integrated evaluation |
| Google Vision AutoML | No | Managed | Basically a managed, simple to use NAS | Transfer learning + NAS, a minimalist UI and w\ integrated evaluation |
| DataRobot | No | On-premise/Managed | An integrated platform with XAI, Inference server, Model and Experiments management | AutoML part seems to be an HPO++ w\ integrated evaluation and XAI and a lot of other stuff |
Fundamentally, AutoML is trading computational budget (or time) for expertise. If you have no idea how to solve a problem, you will opt for the largest possible search space and wait for the search to finish. On the other hand, if you want to cut your expenses for powerful servers, or don’t want to wait for a week until the results arrive, and know some things about your problem, you can reduce the search space and arrive at a solution faster.
AutoML should really be treated more like an exploration tool rather than an optimal model generation tool. It’s not an alternative to a data/ML professional.
AutoML – The good parts (pros)
Alright, I think we have established that AutoML is not a panacea for all ML issues. Then what is AutoML good for?
Speeding up the model exploration stage
Let’s be honest, for most of us more often than not, we are usually not especially experienced in the domains we’re working on. Note that by domain I don’t mean computer vision, NLP, or time series, but rather advertising, e-commerce, finance, cell biology, genomics, and the list can go on for much longer. To add to the challenge, businesses require quick and impactful results.
I have a semi-personal story on how AutoML can bridge the gap between those with expertise and those without. A few years ago, I was at a summer school about Deep Learning and Reinforcement Learning. The organizers arranged a Kaggle competition, basically trying to forecast some time series. I intentionally omit details, you know, it’s semi-personal so… Anyway, there were PhDs, and postdocs, all trying to fit exceedingly complex models, some others were focusing on creating meaningful features. I, for having somewhat shallow knowledge of working with time series, and pure laziness decided I could just use AutoML, namely TPOT. Without much EDA beforehand, and even less so feature engineering. My result was in about the 50th percentile. Now, what do you think the winning submission was? Also TPOT, but with basic outlier removal, converting dates and times to categorical features like is_it_weekend and the likes of it, and running TPOT for 2 days.
The moral of the story – if you lack subject matter expertise, or time to learn it, or are just lazy, AutoML is a fairly good starting point. It also frees up time to work on those features, and as seen from my story, features do indeed make a difference.
Although my story suggests it, it’s not always about delivering the final model, sometimes analyzing the generated candidates for some patterns can be of help too. For example, whether the best solutions use Naive Bayes, Decision Trees, Linear Classifiers, or maybe the AutoML tries to create increasingly complex ensembles, meaning you would also need a very expressive model to solve your problem.
A very good baseline
So, you’re working on a new ML project. The first thing you do, model-wise – you implement a simple heuristic baseline and see where you stand. Second, you try a simple ML solution and analyze how much it improves the baseline. One thing you can try to do after this stage, at least what I like to do, is to try to estimate what would be your upper bound in terms of predictive performance, and let an AutoML solution squeeze the most out of your data and preprocessing.
Not only does it sometimes deliver superior results quickly, but it also shifts your perception towards working on better features.
Note that sometimes you don’t have the resources or are constrained by some other factors. So YMMV, but do keep in mind this use case for AutoML when working on new projects.
Identify quickly – what works and what doesn’t?
The space of possible combinations of feature transformations, algorithms, their hyperparameters, and ways of ensembling said algorithms create an immense search space of possible ML models. Even when you know what solutions can work and what can’t for a given problem, it’s still a vast search space. AutoML can help to fairly quickly test what configurations are more likely to work.
“How?” – you may ask. By running AutoML multiple times, and tracking:
- what configurations get picked more often,
- how often,
- what is dropped,
- how quickly is it dropped,
- and so on.
In a way, this is some kind of meta-EDA. One might say – Exploratory Model Analysis.
Now, why would you be interested in it? We want the best model, why not get straight to it? Because what we should aim for isn’t one good final model, but an understanding of what works, and what doesn’t. And based on this understanding, we can better solve problems further down the line. Even with AutoML, no one exempts you from such lovely issues as needing to periodically retrain your models on new data and also trying to reduce budget expenditure on ML.
AutoML – The bad parts (cons)
A false sense of security
Honestly, this is the thing I hate the most about AutoML. It feels like magic and makes you lazy. And just like any automation, the more you use it, the more catastrophic it is when it fails.
Because of this, it’s easy to introduce data bugs. And due to AutoML’s sometimes opaque nature, these bugs are very hard to spot.
I have a personal anecdote about this, too – one that I will probably never get tired of recalling. We were working on a cell classification problem, where the distinction between the positive and negative classes was tough to observe even for a human. The images could really be at least somewhat accurately classified only by SMEs. We were trying for a few months to create a computer vision model to automate this task. The results weren’t good. Even with the most custom-built solution, which took into account various properties of our dataset and was capable of learning from small amounts of data without overfitting, the accuracy was close to 69%. On a binary classification problem.
At that stage, we had the opportunity to use Google Vision AutoML which was still in beta. The quick run results were a bit worse than ours. Eventually, we decided to run the full training, which was a bit pricey, and to make the most out of our data, we manually augmented the images to increase the dataset size. Lo and behold, 98.8% accuracy. Great success!
Only I was skeptical about it. After months of failed experiments, hundreds of hyperparameters tried, and dozens of methods used, I couldn’t believe some NAS could beat the problem, and do so by light-years. My superior was preparing to announce our outstanding results to the investors and other stakeholders. I insisted we inspect what was going on. A few weeks later, with a few dozens of partially occluded images, total confusion, and despair, I figured it out.
We manually augmented the dataset before using it with Google Vision AutoML, but we didn’t manually specify the splits. As a result, augmented versions of the same image were in training, test, and validation splits. The model just memorized the images. Once we fixed it and ran it again, we got ~67%.
The moral of the story – don’t get comfortable with AutoML, it’ll bite you in the back.
Prone to over-optimization/over-fitting
Depending on the nature of your data, and your model validation setup, some AutoML solutions can easily overfit. By the nature of data I mean its properties like label distributions, how many outliers you have, and the overall quality of your dataset. To be fair, often it’s not the tool’s fault, but yours, meaning most of the time the cause of overfitting is in your evaluation setup. So watch out how you evaluate candidates, how you split your data, and if working with time-series – I don’t envy you. Treat the AutoML process like hyperparameter optimization, and split your data accordingly using something like nested cross-validation.
You can find a comprehensive guide how to properly evaluate any machine learning model here in this post.
Too much emphasis on optimization
As mentioned a few times already, the correct way to think of AutoML is as an enabler that lets you focus more on the data side of things. But in reality many fall trap to the idea that model hyperparameters, and the model in general, are the most important factor in an ML project because AutoML solutions can sometimes show excellent improvements, reinforcing this idea.
The resulting models can be tedious to deploy
I once had the opportunity, or misfortune, depending on when you ask me, to work on ad price forecasting. And eventually, I tried using AutoML, namely TPOT. It ran well and gave pretty good results, so we decided to have our best-performing model deployed. I was asked to convert the model into something that a Golang or, at least, a Java backend would understand because deploying Python services was a no-go.
After a few hours of research, I discovered PMML, plus I already knew about ONNX. Long story short, PMML-capable libs vary a lot in what models can they read. So, while my ensemble Python model generated by TPOT was somewhat unproblematic to convert to PMML format, making a Go program understand it was impossible. Why? Because the Go lib didn’t know how to work with ensembles, preprocessing, and most models except for some decision trees, linear classifiers, and maybe Naive Bayes. As for ONNX, it also proved problematic to convert a scikit-learn ensemble pipeline to ONNX.
Often AutoML candidate models grow very complex, and converting them into anything becomes a headache. That’s why a lot of production ML is based mostly on linear classifiers, Naive Bayes and random forests, and GBDTs. You will rarely if ever see some complex stacked ensemble of different classifiers. They are a priori slow and very hard to make fast or compatible with non-Python environments.
Hard to analyze/debug the model
Recall the Google Vision AutoML story. Google didn’t have any facilities to deeply inspect models, a la XAI. Also, there was no way to obtain some kind of interpretability or explanations of predictions for individual images. As a result, I was stuck with obfuscating parts of input images and analyzing the predictions. Generally, explainability and debugging tools for AutoML are a special problem. AutoML-generated models tend to be quite complex, thus hard to analyze. Additionally, most of the time the complexity hits twice, because a complex model will take more time to run predictions, and this, in turn, makes obtaining explanations using black-box analysis tools even more burdensome.
If you’re interested in some of the most popular black-box XAI tools, check out this post.
AutoML vs Data Scientists
Before I give you some numbers, just keep in mind that depending on the problem you’re trying to solve, your experience with AutoML will vary greatly. So, let’s dive in.
A word on AutoML benchmarks
The literature on AutoML benchmarks is fairly scarce, and most often it compares the performance of AutoML solutions omitting the performance of humans. Also, the studies are mostly about tabular datasets. Thankfully, we do have some work in establishing standardized ways to assess the performance of different AutoML solutions.
First, there’s the AutoML benchmark, and then there’s also a so-called Kaggle benchmark, which you can find examples of in this paper and in this Medium post. For information on the use of AutoML/NAS in computer vision and text classification tasks, the easiest thing to do is to check the results of the NAS Bench(mark) and a few other competitions. Still, not much comparative analysis between people-led and algorithm-led designs.
Is all hope lost?
No. On one hand, you can always try to run your models against the datasets mentioned above and see how good/bad you are against AutoML. But of course, this isn’t the answer you’re looking for. Enter “Man versus Machine: AutoML and Human Experts’ Role in Phishing Detection”. I’ll give you the gist of it, and a personal remark.
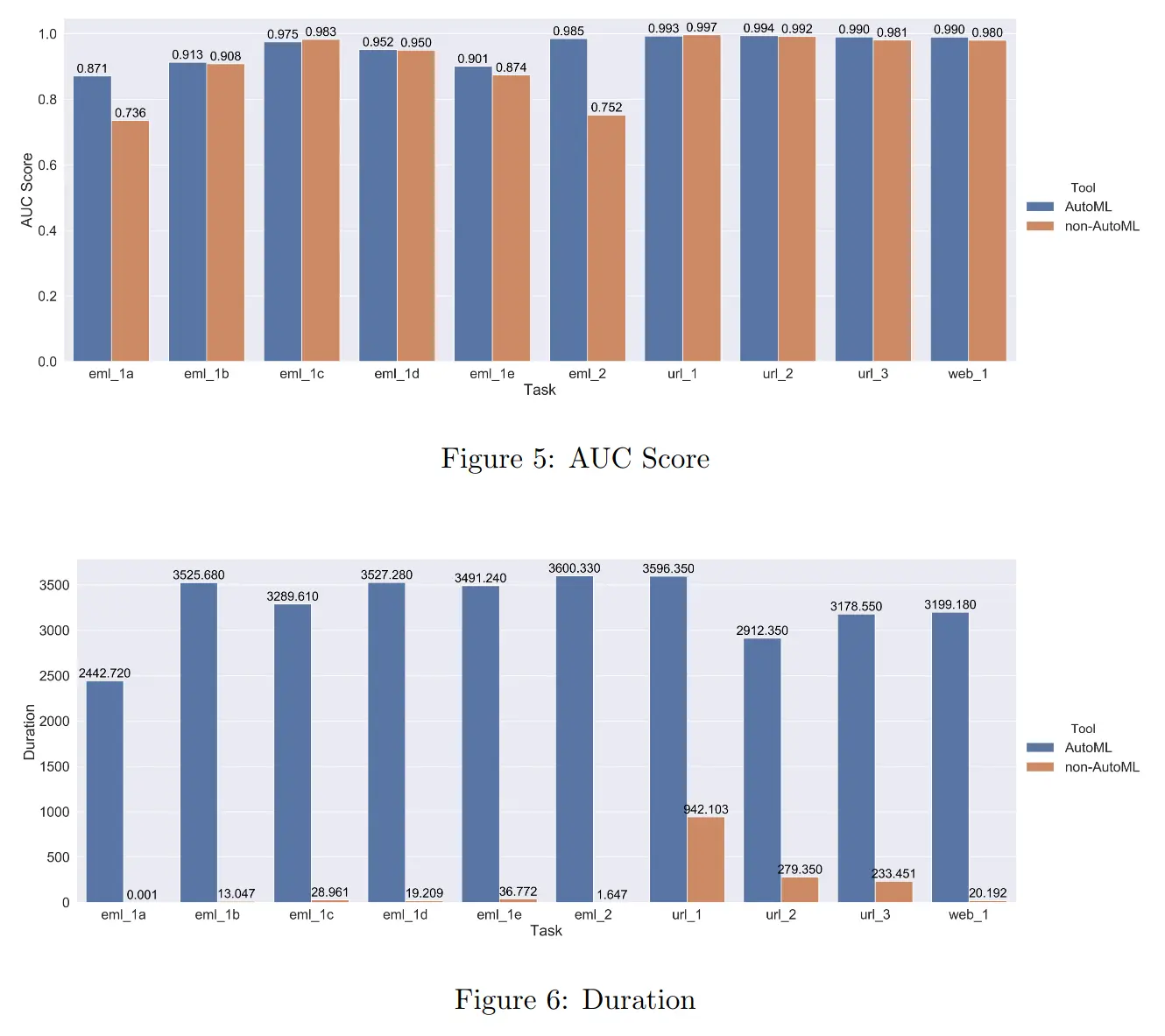
* One thing to note – Duration is calculated as the time it takes for a model to be trained on the given dataset.
-
The authors conclude that AutoML models significantly outperform people when the dataset these solutions are applied to have some overlap in their classes and generally show high degrees of non-linearity. In other words, hard datasets. Otherwise, the performance is on-par with not using AutoML. They also claim that AutoML solutions usually take much longer to create high-performing models compared to non-AutoML.
-
And here’s the catch, the authors don’t mention the time it takes to come up with a high-performing model. Why you may ask? Because for their non-AutoML solutions they take existing scikit-learn algorithms and don’t tune them at all. What does it all mean? First, take the duration conclusion with a grain of salt. Second, AutoML will only ever make sense for hard datasets, with noise, overlapping classes, and high degrees of non-linearity. Otherwise, you’ll be better off with the default settings of some off-the-shelf algorithm.
Their findings of the correlation between dataset complexity and AutoML advantage are quite in line with my personal experiences and the results of AutoML Benchmark, in which on more complex datasets some AutoML solutions have a 10%+ advantage in AUC and accuracy over manually created models. As you may recall from my story in the first part of AutoML cons, what took me a few months of work, Google’s AutoML almost matched in 24 hours.
How does all of this information help you? If you know your dataset is well-behaved, maybe don’t bother with AutoML. But how would you know? You can try running a few classic ML models, and see how their cross-validation performance varies. Or maybe just “look” at your data.
Personally, I use AutoML first in the beginning as a quick exploration tool, and then when all hope is lost. Never in between. To help you make up your own mind about AutoML, check out the links below, and run experiments.
Further reading – benchmarks of AutoML methods, including against humans:
- AutoML is Overhyped
- AutoML Faceoff: 15 Humans VS 2 Machines. Who won? | by Norm Niemer | Towards Data Science
- Compare popular AutoML frameworks on 10 tabular Kaggle competitions | by Piotr Płoński | Towards Data Science
- [1907.00909] An Open Source AutoML Benchmark
- [2108.12193] Man versus Machine: AutoML and Human Experts’ Role in Phishing Detection
- [2003.06505] AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
- [1902.09635] NAS-Bench-101: Towards Reproducible Neural Architecture Search
What if… everyone would use AutoML, always?
Before we dive into this thought experiment, recall that AutoML works by trading computation for expertise. If we are clueless and have tons of computing power, this is “The Tool”. Let’s analyze what would happen if we went all-in with AutoML in the case of a more classic, established business, and in the case of an innovative company.
Major enterprises, like Ford
Depending on what department would use AutoML instead of their existing ML/DS tools, we might have somewhat good results, for example in marketing and sales, somewhat worse results in logistics and planning, and probably absolutely rubbish results for stuff like ADAS, which is advanced driver assist systems and simulation software. Besides, the increase in computing power required for the company to run these AutoML solutions would most certainly set them back by a non-trivial amount of cash.
And even if they would have the money and irrationality to go all-in on AutoML, it still would be a bad idea, due to strict requirements for model interpretability, which a complex ensemble model resulting from AutoML just can’t give. Hard pass.
Innovative companies, like Palantir
If we’re talking specifically about Palantir, I believe with or without AutoML, their software doesn’t really care, because it’s about integrating and smartly using the data assets of an organization. Still, most of the analysis doesn’t require very advanced ML algorithms, so using AutoML would be a waste of money. Why use it when the best model is still going to be a linear regression or a decision tree. Why you may ask? Because their clientele is organizations that value model interpretability very much, again.
For any other innovative company, AutoML would have its place, but still within some serious limits. A lot of the time, the problems faced by these organizations can’t be simply formulated as supervised classification or regression, which makes it tricky to use AutoML.
The more innovative the use case, the harder it is to use off-the-shelf solutions. Can you imagine using an open-source AutoML tool to develop new drugs, or composite materials, or optimize the placement of transistors on a specialized chip? Me neither. These tasks can easily and should be treated as research directions. Is anyone in need of a startup idea?
An analysis
Maybe you noticed that a major problem for industry adoption of AutoML is interpretability. You might think “Oh, but maybe they haven’t heard about stuff like SHAP, or XAI (Explainable AI) in general? That ought to change their minds”. I assure you, it won’t. Not soon, anyway.
You see, there’s a major difference between model interpretability and explainability. The former means that the model can be understood, as it is. The latter usually means either that there’s a way to infer why a certain prediction was made, or in more academic/cutting-edge cases, that a model will “tell you” the reasoning behind its prediction. And maybe you already see the problem here. No one can guarantee you that the explanation is correct.
This is the reason why, for example, there were thousands of people developing neural network-based computer vision models to detect if a patient has COVID based on their X-ray scans, and yet no major medical institution was using these. Doctors need to understand very well why the predictions were made. Same as legal, accounting, sales, marketing, and all the rest have different, sometimes non-negotiable requirements about model interpretability. And that’s why organizations are still big fans of linear models and decision trees and shy away from dense Neural Networks.
So what would be a good use case for AutoML?
Now, let’s see some concrete use cases which can benefit the most from AutoML:
Batch jobs
Most AutoML tools do not take into account model complexity/compute requirements, as a result giving you very well-tuned models which can be extremely slow or computationally demanding. Because of this, using such models is impossible in interactive or streaming scenarios, so what you’re left with is using them for batch jobs.
Maybe running ML as batch jobs sounds not that exciting, especially after you read about incredible feats of engineering of deploying ML models directly interacting with users, maybe even on edge devices, or how people are using ML models in streaming scenarios to process billions of events in near real-time, but trust me, a lot of businesses have processes that are absolutely fine with running on a schedule once in a few hours, days, or even weeks. You’ve certainly heard that quickest results beat most accurate results when it comes to business, but there are plenty of situations where accuracy is more critical than time.
Testing the waters for a problem
I said before, and I will say again – AutoML is best suited for quick prototyping. It’s my favorite use-case for AutoML and one that helps me assess where an upper bound of performance might be, with my current dataset and pre-processing/feature engineering in place. When you adopt this mindset, you slowly turn towards a more data-centric ML/AI paradigm because you just assume that you will always get an optimized model.
Keep in mind that this should be done after the EDA stage. Also, if possible, try to reduce the search space, based on your EDA. If there are no significant correlations between attributes and the target variable you can confidently drop linear classifiers from the search space. What I like doing is running a few quick experiments with a reduced search space using an AutoML tool, with only the simplest models, with different random seeds, because of replicability, and see what are the best performing models. Based on that, I can adjust the search space for the next runs.
Takeaways
AutoML is both a blessing and a curse. As with any tool, it can be used right to the greatest advantage, or it can be misused and then bad-mouthed.
One thing to keep in mind is don’t abuse it.
It can be tempting to throw AutoML at any problem, even before analyzing your data or understanding your problem. Don’t be that person.
Another important thing you should get from this blog post: Invest all the time you save using AutoML on feature engineering. Think of it this way, if you would have the best model for your dataset, what else can you do to improve the performance of your machine learning system? Obviously, you can fetch more data or ensure that the data is of higher quality or have more informative features. Of course, AutoML won’t give you a perfect model, but the rationale holds. With modeling (almost) out of the way, and better performance still possible, you should focus on improving your data and features to reach those performance objectives. And if the results look too good – debug it.
Most importantly, make sure you understand very well the business requirements. So before running AutoML for hours on powerful CPUs and GPUs, take a few minutes to discuss whether your users will appreciate the slight increase in predictive performance, and won’t mind the lack of model interpretability.
As you can see, depending on who you ask, AutoML can mean quite different things. I recall the first time I figured that most of what is marketed as AutoML can be done with a multi-core workstation, a hyperparameter optimization library, and all of it wrapped in a simple UI, I was somewhat disenchanted. As long as it works for you, I guess.
References
- Data Prep Still Dominates Data Scientists’ Time, Survey Finds
- Do data scientists spend 80% of their time cleaning data? Turns out, no? – Lost Boy
- How I Spent My Time As Product Data Scientist | by andrew wong | Human Science AI | Medium
- What do machine learning practitioners actually do?
- Dataiku Documentation
- Automated Machine Learning – DataRobot AI Cloud
- H2O Driverless AI
- AutoML: Automatic Machine Learning — H2O 3.36.1.2 documentation
- An Opinionated Introduction to AutoML and Neural Architecture Search · fast.ai
- [1908.00709] AutoML: A Survey of the State-of-the-Art
- AutoML is Overhyped
- AutoML Faceoff: 15 Humans VS 2 Machines. Who won? | by Norm Niemer | Towards Data Science
- Machine Learning Applied to Medical Diagnosis